Motivation
Energy Access Planning
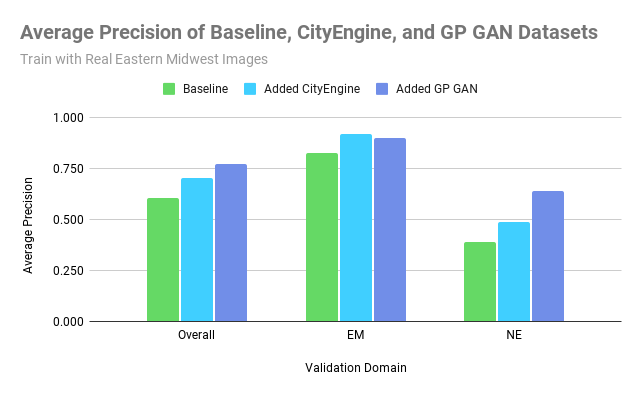
Access to clean and affordable energy (one of the seventeen UN Sustainable Development Goals) is becoming increasingly critical, especially for promoting economic development, social equity, and improving quality of life. Further, it has been shown that electricity access is correlated with improvements in income, education, maternal mortality, and gender equality. Yet, worldwide, 16% of the global population, or approximately 1.2 billion people, still don’t have access to electricity in their homes. This map from the World Bank in 2017 highlights the uneven distribution of energy access, with the majority of those without electricity access concentrated in sub-Saharan Africa and Asia.
One of the first steps in improving energy access is acquiring comprehensive data on the existing energy infrastructure in a given region. This includes information on the type, quality, and location so that energy developers and policymakers can then strategically and optimally deploy energy resources. This information is key for helping them make decisions about where to prioritize development, and whether they should use grid extension, micro/minigrid development, or offgrid options to bring electricity access to new communities.
However, this critical information for expanding energy accessibility is often unattainable or low quality. A solution to this issue is to automate the process of mapping energy infrastructure in satellite imagery. Using deep learning, we can input satellite imagery into an object detection model and make predictions about the characteristics and contents of the energy structure in the region featured in the image, providing energy experts with the necessary data to expand electricity access.
Object Detection
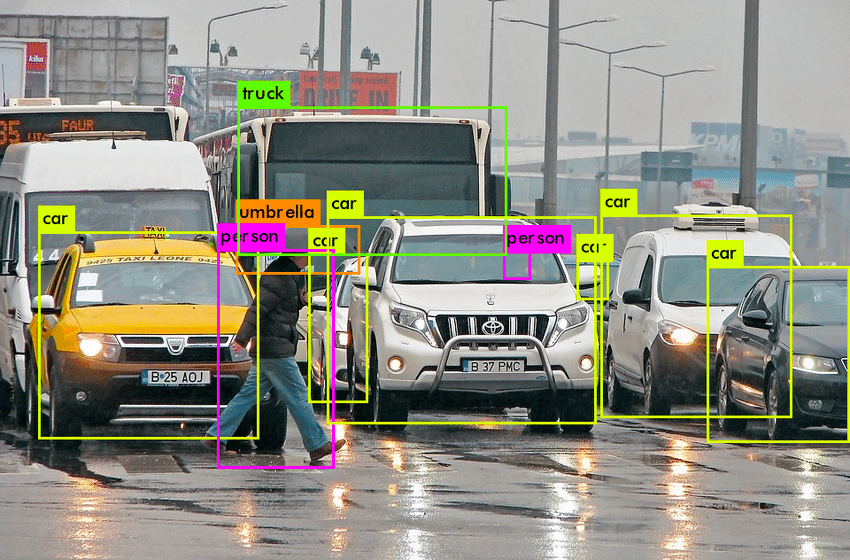
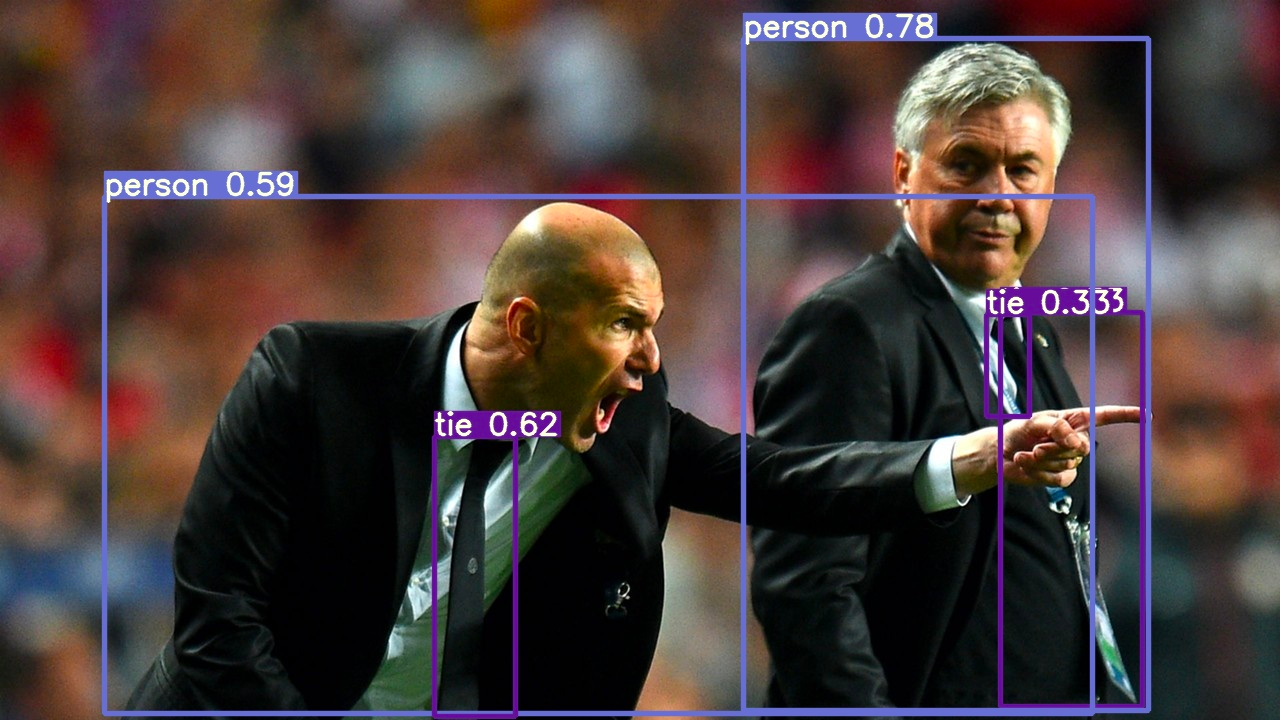
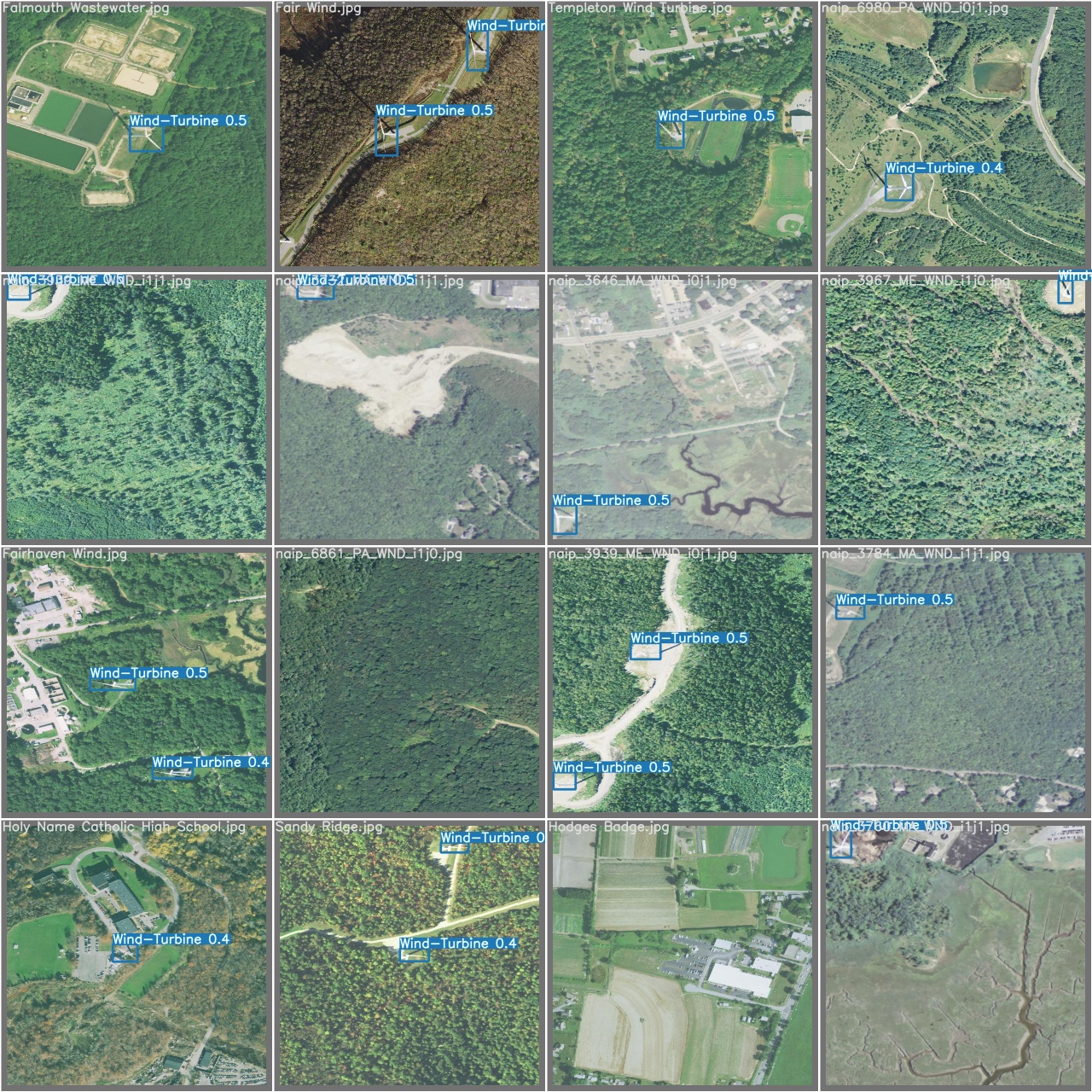
Object detection consists of classification (identifying the correct object) and object localisation (identifying the location of a given object). Our project has a particular emphasis on object detection, as we seek to improve the detection of energy infrastructure in different terrains as a part of expanding energy access data. Object detection models analyze the scenery of photos and generate bounding boxes around each object in the image. In doing so, it classifies each object and assigns a confidence score based on the accuracy of its prediction. The model predicted that each of the green, yellow, orange, and pink boxes in the image on the left would indicate different objects, being a truck, a car, an umbrella, and a person. Based on examples provided to it, the model learns how to predict these boxes and classes. We refer to these labeled images as ground truth as they contain boxes that denote every object's class and the location within the image.
Applying Deep Learning to Overhead Imagery
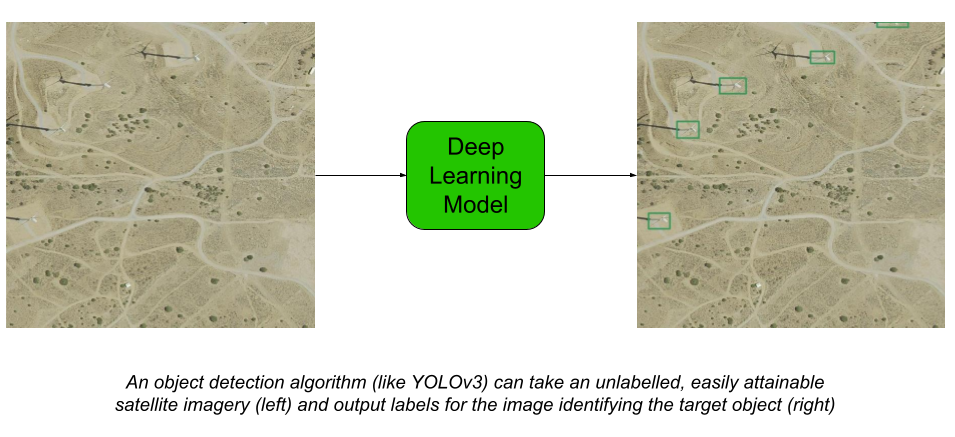
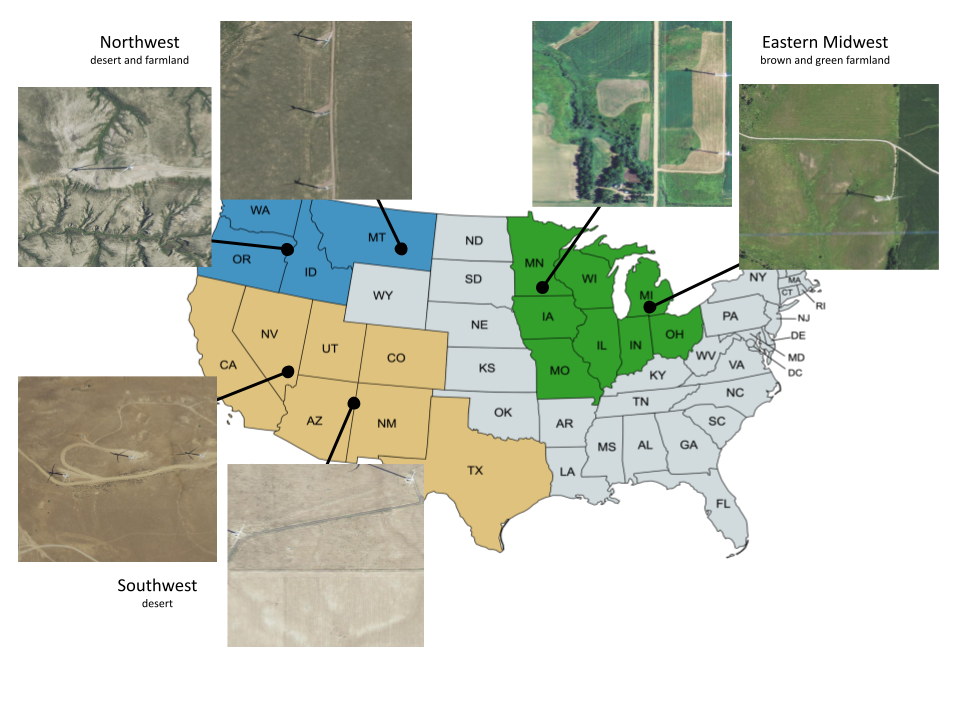
After training our object detection model, we can apply it to a collection of overhead imagery to locate and classify different energy infrastructure across entire regions. In our experiments, we test our ability to detect wind turbines to maintain consistency with previous experiments. While we could demonstrate energy infrastructure detection for any number of types of electricity infrastructure, wind turbines were chosen due to their relatively homogeneous nature as opposed to different power plants and other energy infrastructure. Additionally, our dataset was limited to the US, as there is a wealth of high resolution overhead imagery available throughout the US. Ultimately, the methods used to improve object detection of energy infrastructure will be expanded to more energy infrastructure and tested on more regions, however, limiting the the infrastructures to wind turbines and using readily available US imagery helps to quickly provide performance benchmarks for our real and synthetic datasets.
Challenges with Object Detection
Problem 1: Lack of labeled data for rare objects
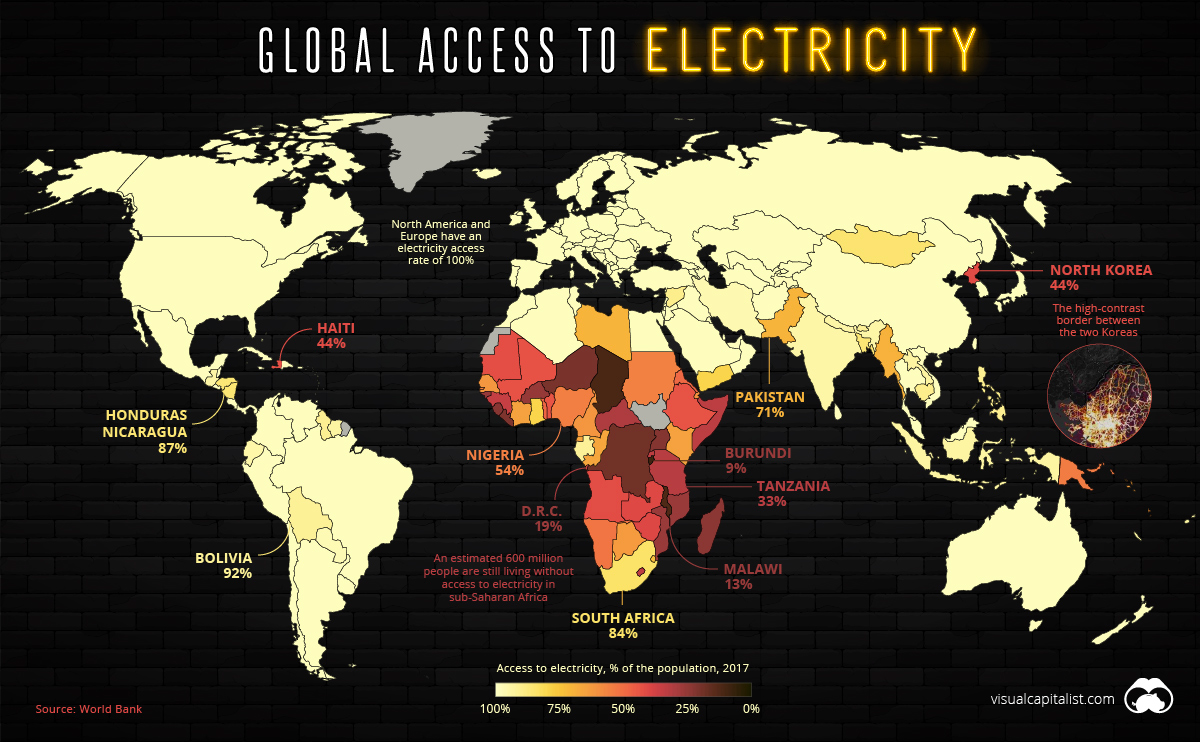
While the potential of object detection seems promising, it presents two main challenges. The first is that properly training the object detection model requires thousands of already labeled images (images in which the location of the target object is known and identified via an annotation). According to Alexey Bochkovskiy, developer of the highly used and precise YOLOv4 object detection model, it is ideal to have at least 2000 different images for each class to account for the different sizes, shapes, sides, angles, lighting, backgrounds, and other factors that could vary from image to image. Thus, in order to make the object detection model best generalize, the model will require 1000s of training images per energy infrastructure. Because many types of energy infrastructure are rare objects, obtaining and annotating such a large quantity of satellite images featuring these infrastructures manually is expensive in terms of both time and cost.
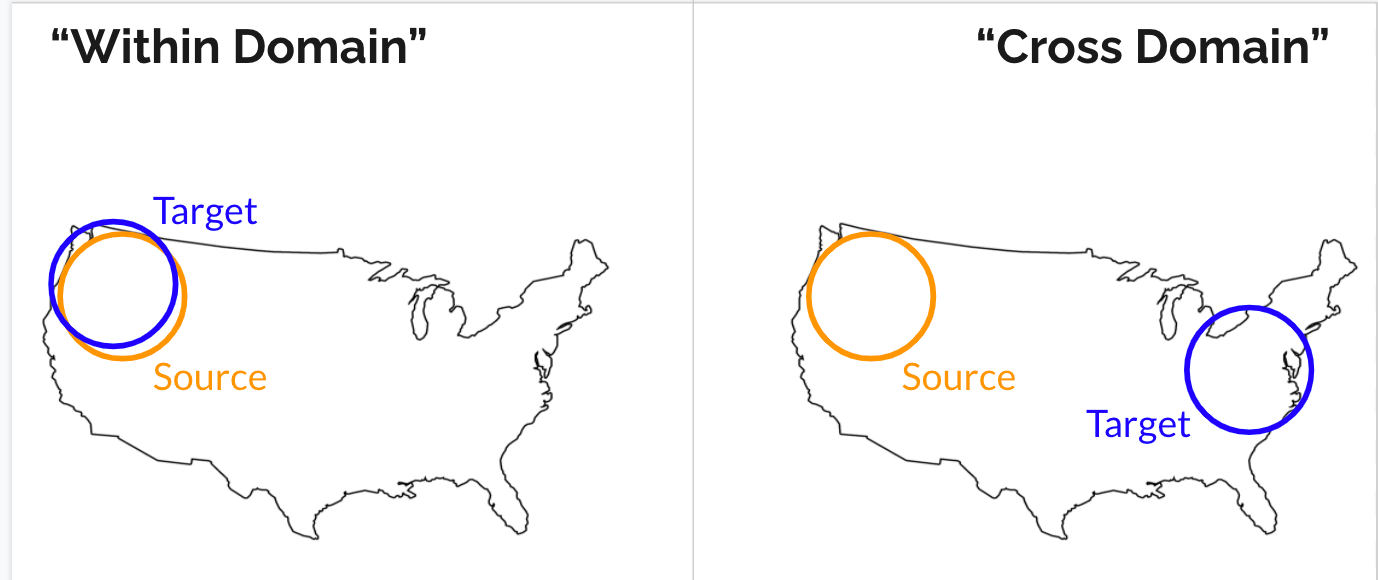
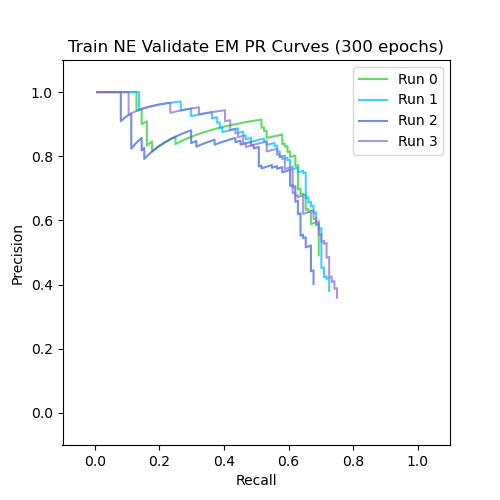
Problem 2: Domain adaptation
The second challenge we face is that in training an object detection model to detect energy infrastructure in certain regions, our training set and testing set must come from different locations and thus may have differences in geographical background and other environmental factors. Without being properly trained for the test setting, object detection models are not great at generalizing across dissimilar images yet. What this means is that if we train our model on a collection of images from one region, featuring images with similar background geographies, the model will then be able to perform fairly well on other images with those same physical background characteristics. However, if we then try to input images from a different region with different geographic characteristics, the model's performance becomes significantly worse, since it hasn’t been trained with images containing those specific background features.

Image from: 2020-2021 Bass Connections team.
Proposed solution: Synthetic Imagery
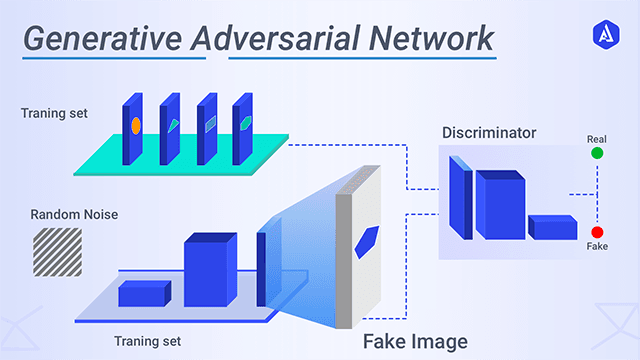
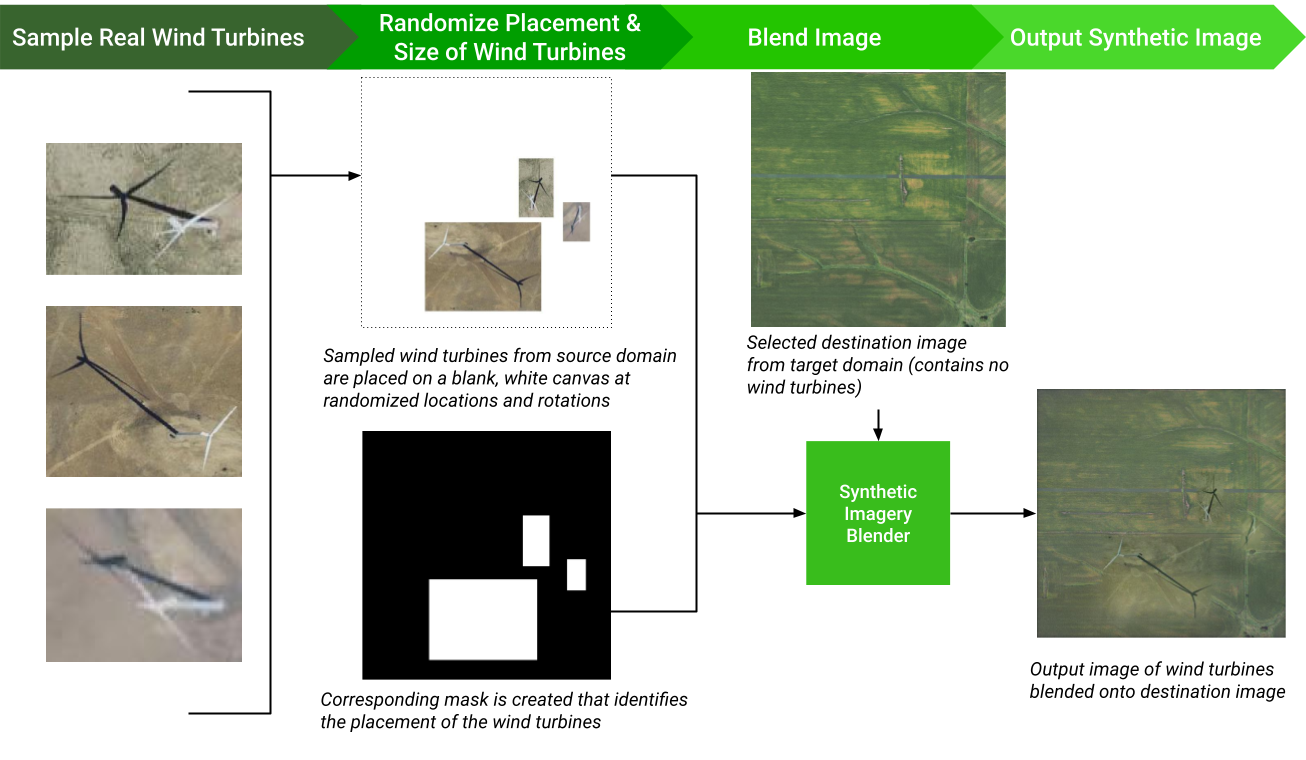
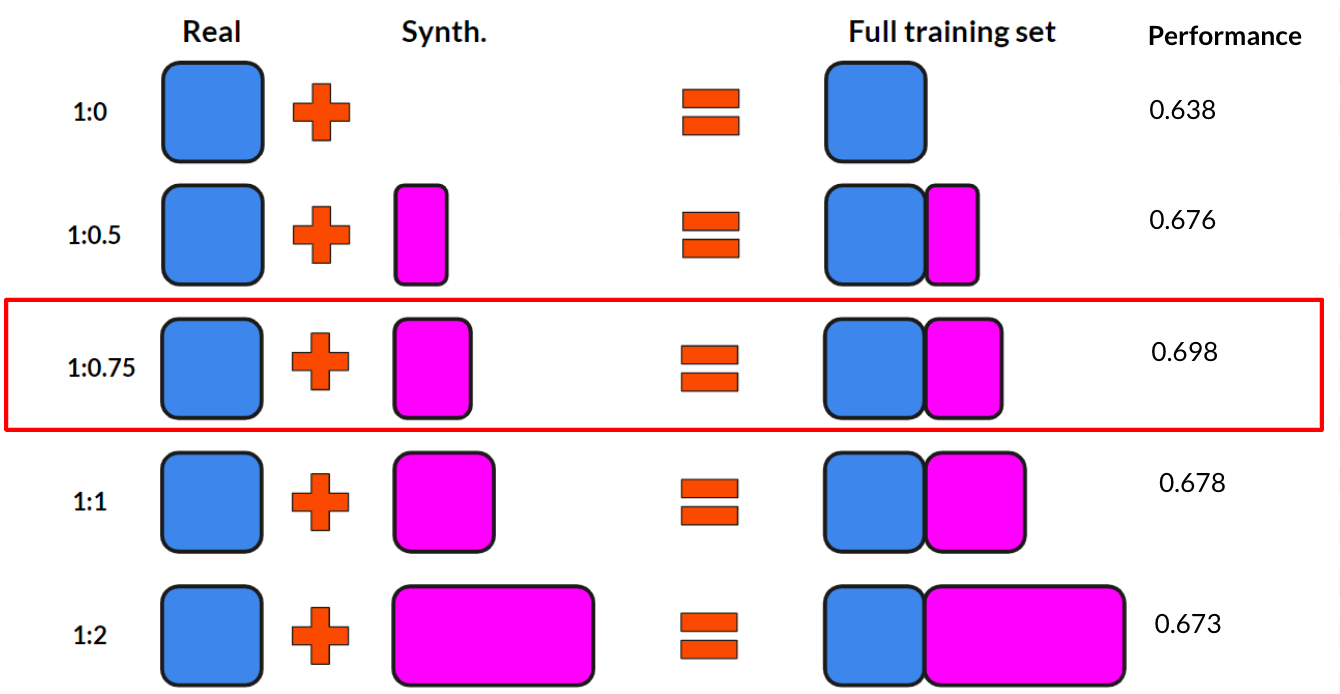
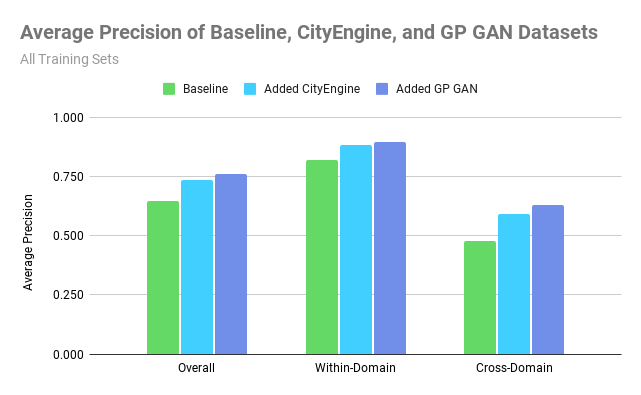
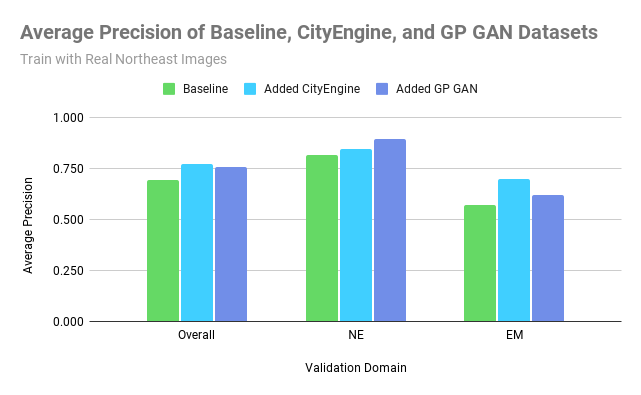
Our proposed solution to address these two problems is to introduce synthetic images into our training dataset. These synthetic images include a labeled target object implanted into the background of the target domain, so that even if we don’t have real labeled images from the target domain, we can create close imitations.. The synthetic images supplement the original real satellite imagery dataset to create a larger dataset to train our object detection model, diversifying the geographical background and orientation of energy infrastructure that the model sees. We generate these synthetic images by cropping the energy infrastructure out of satellite images and using a Generative Adversarial Network to blend them into a real image without any energy infrastructure from one of the target geographic domains.

Previous work
For five years, the Duke Energy Data Analytics Lab has worked on developing deep learning models that identify energy infrastructure, with an end goal of generating maps of power systems and their characteristics that can aid policymakers in implementing effective electrification strategies. Below is a timeline of our team's progress.
-

2015-2016
Our Humble Beginnings
In 2015-16, researchers created a model that can detect solar photovoltaic arrays with high accuracy [2015-16 Bass Connections Team].
-

2018-2019
Transition to New Infrastructures
In 2018-19, this model was improved to identify different types of transmission and distribution energy infrastructures, including power lines and transmission towers [2018-19 Bass Connections Team].
-

2019-2020
Expanding Our Geography
Last year's project focused on increasing the adaptability of detection models across different geographies by creating realistic synthetic imagery [2019-20 Bass Connections Team].
-

July 2020
Improving Our Perfomrnace
In 2020-2021, the Bass Connections project team extended this work, trying to improve the model’s ability to accurately detect rare objects in diverse locations. After collecting satellite imagery from the National Agriculture Imagery Program database and clustering them by region, they experimented with generating synthetic imagery by taking satellite images featuring no energy infrastructure and placing 3D models of the object of interest on top of the image, and capturing a photo that mimicked the appearance of a satellite image [2020-21 Bass Connections Team]. Their paper, Wind Turbine Detection With Synthetic Overhead Imagery, was published in 2021 by IGARSS.
-

Now
Our Work
In our project, we build upon this progress and try to improve the 2020 Bass Connections team and 2021 Data Plus team's ability to enhance energy infrastructure detection in new, diverse locations.
Key Contributions
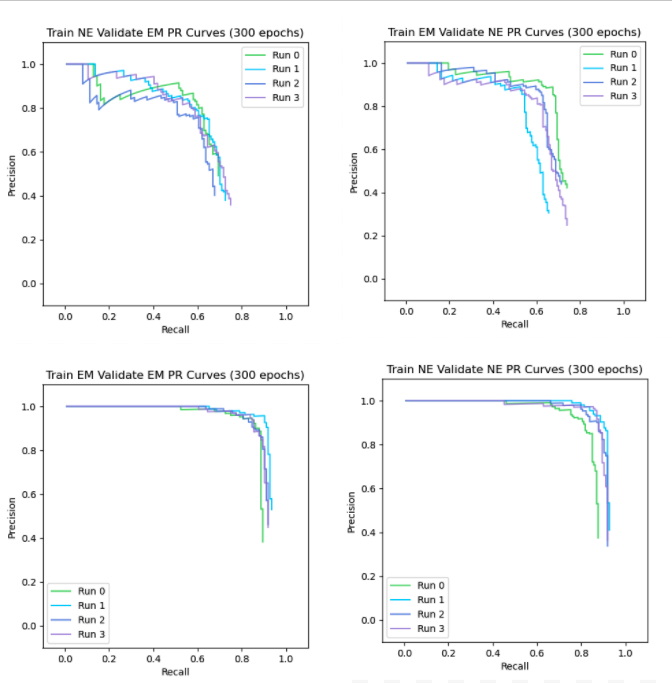
We propose a new method for unsupervised domain adaptation that is comparable to state-of-the-art domain adaptation techniques and methods. We created a large, diverse, publicly-available dataset for wind turbine and transmission tower object detection. Our dataset encompasses 5 large geographic regions of the United States, and is the first of its kind for both wind turbines and transmission towers. We found that adding unlabeled background imagery was beneficial to the object detection performance of neural networks in the context of domain adaptation with remote sensing data.
.png)